


Pagan / Acc Chapter 2.1
Listing Benchmarks for Distributed Computing

Centralized singleton AI is to be feared. A man can dream of a different world…

Yet there are limits to dreams. They can be slow.


The cost to train ain't cheap…

Some efficiency can be squeezed out to catch up, but not to reach beyond the corporate state of the art.



It looks like the GPUs of the world need to unite if stealing is to be avoided...


I discussed self-hosted AIs before but they trail far behind the cutting edge. We need to change this.
What is BOINC? It's a Berkeley open source project that does science by splitting computational tasks in astrophysics and other domains into small "jobs" to volunteer devices.
The 3 benchmarks for distributed computing
These are SETI@home - extraterrestrial intelligence finding, Rosetta@home - protein structure prediction at University of Washington, and Folding@home - also about proteins, and currently based at the University of Pennsylvania.
Let's briefly examine each of these.
SETI@home
You probably have heard of the SETI project, and SETI@home is a support project to it.
Their wikipedia site provides some stats about the userbase: SETI stats archived in March 2020.
Active users Decrease 91,454
Total users Increase 1,803,163
Active hosts 144,779
Total hosts 165,178
And their website provides a 38.957
What about the results? Wikipedia says less than 2% of the sky has been surveyed.
The team behind it, or at least the github organization contains only 9 people.
The project's interface looked like this:

or actually LOOKED, as it's been put on indefinite hiatus.
Rosetta@home
Rosetta@Home stats are broader than SETI's. Here we have compute mentioned.
Users (last day ): 1,383,796 (+4)
Hosts (last day ): 4,526,806 (+23)
Credits last 24h : 3,895,698
Total credits : 148,596,647,816
TeraFLOPS estimate: 38.957
Rosetta-at-home's github repo highlights the increased activity during COVID.
That is not the historical peak though, Project Wikipedia website mentions the collective compute increased up to 1.7 petaFLOPS.
That record is still small and slow compared to its big brother, Folding@home.
Folding@home
The stats website didn't load the data for me, but project Wikipedia page says in April 2020 it had 2.5 exaFLOPS of x86 processing power.
The project is massive, also on Twitter, with 31K followers, compared to Roesetta@Home's 5,6K.
It is only partially open source. They justify this by saying it would be too easy to create fake data.
Checkout their github repositories, both client and node.
Comparing with GPT
A comprehensive reddit post suggests the cost of training GPT-3 was $5M, and 1024 A100 GPUs would take 34 days. Narayanan, D. et al. July, 2021 Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. suggests 140 TFLOPS per GPU, so more than 1 exaflops.
Redirecting Folding@home at peak popularity - April 2020 would recreate GPT-3 equivalent in 17 days.
It seems we could make this. Surely someone thought of this earlier, right? Let's scan the lists of BOINC projects for AI related topics.
Distributed AI projects?
At the time of writing this post Wikipedia has these lists, with only 3 AI related distributed projects in total.
A list of volunteer computing projects and a list of grid computing projects contain 3 projects in total. These are Comcute - not BOINC based, active between 2010 and 2016, FreeHAL chatbot terminated in 2011, and oddly named Artificial Intelligence System that finished in 2010.
Doing some more digging, I found Distributed.net, a framework that allows GPU time sharing. Their full computing power according to the wikipedia website was 1.25 petaFLOPS in August 2019. The project they use it for is brute-forcing RC5 cipher with a 72 bit key. Such a useless spending of time.
If this was a murdery mystery, we'd be asking now 'who is killing off all the decentralized computing projects'? The answer is: cloud.
Aaand also the 1exaFLOPS needed to train it in reasonable time. With 1petaFLOPS you'd need 1000x more time than 34 days.
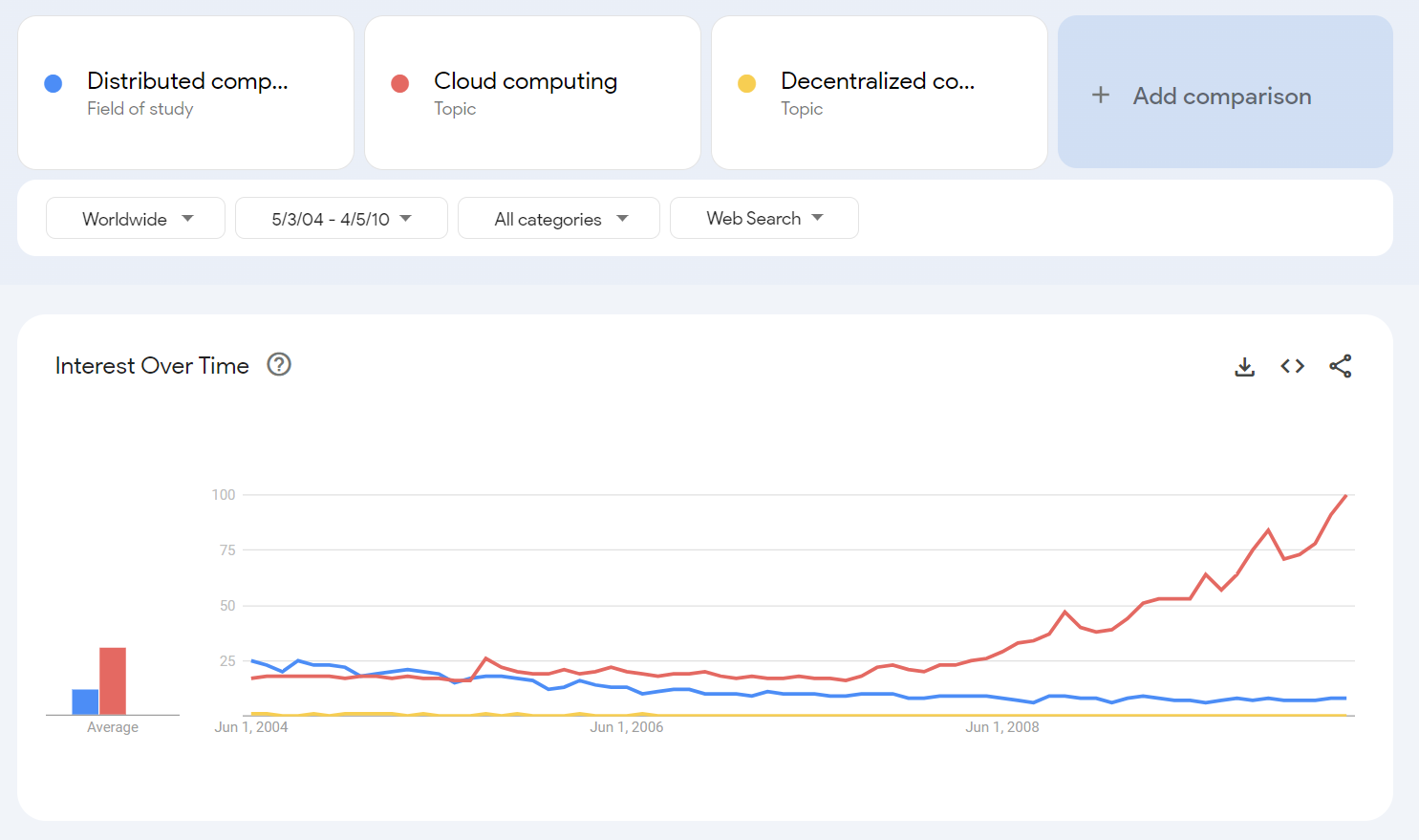
Approaching from the other direction, the artificial intelligence projects list does not feature any decentralized ones.
The conclusion from this analysis is that AI specific distributed projects are scarce, but there is a good track record in other domains, enough to computationally compete with OpenAI. Now the question is technological and organizational.
What do we want exactly to reach the dream of 'AGI on a single GPU'?
Border conditions
Decisions need to be taken on the architecture of the AGI network, storage and source of training.
Fortunately transformer architecture is easily parallelizable, that's one of the reasons GPT took off. BOINC works in a quite centralized way in terms of data control, even if compute is distributed. Main server sends job packets to the clients, who solve the job and return the answer. That's not the perfect solution we'd have for decentralized AI, we'd prefer nodes that are equal, like with blockchain.
Perhaps some sort of 'proof of training' would be necessary, an asymmetric hashing function where an LLM node tells others a given text has finished training locally and is ready to distribute the updated weights to other nodes.
Training dataset could be just The Pile.
Not enough GPUs? There has been discussion of alternative hardware, not GPUs, for training LLMs, prominently Cerebras - see this article.
Ok so that's the training, what is the incentive model? How do people actually use it? Once you train a model, it's all yours! The biggest hurdle is past!
But not everyone would host a model - there are minimal hardware specifications.
I imagine that as a not-model-hosting node-provider you would verify training chunks and access a limited number of queries each day.
There are 3 processes behind your fun time with ChatGPT: training, fine-tuning and inference.
Training is the heavy step, loading data intially.
Fine-tuning aka lobotomizing is giving the model soul.
Inference is the actual chit-chat, be it python or fanfiction.
People are developing many projects trying to make big models work locally, most without networked parallelism, running only local inference and some fine-tuning.
Corporations are construing 300B parameters projects when you play with a TOY that has 6B! You are WASTING PRECIOUS TIME!
WE CAN BUILD IT! We have the compute
What are the goals then?
The first SMART goal is relatively modest, but includes the core tech and memetic stack, putting us firmly into the linear-ish part of the exponential curve:
100 training machines
1000 teraflops
95% uptime - rivaling OpenAI’s one
fully open source
The 'comparable to GPT-4' would probably be closer to
10^6 machines
1 exaFLOPS
xlr8harder made a cost calculation but he's gone now from twitter, I noted down before that that given 10k users, training a gpt-3.5 equivalent would be $400 per person.
Memetically non-trivial, but doable.
Takeout
GPUs of the world, unite! You have nothing to lose - the winning AI would destroy you first, then all the humans!
Will discuss technical details in the next post. There's no time to be lost anons...

Links to other parts:
rats and eaccs 1
1.1 https://doxometrist.substack.com/p/tpot-hermeticism-or-a-pagan-guide
1.2 https://doxometrist.substack.com/p/scenarios-of-the-near-future
making it 22.1 https://doxometrist.substack.com/p/tech-stack-for-anarchist-ai
2.2 https://doxometrist.substack.com/p/hiding-agi-from-the-regime
2.3 https://doxometrist.substack.com/p/the-unholy-seduction-of-open-source
2.4 https://doxometrist.substack.com/p/making-anarchist-llm
AI POV 3
3.1 https://doxometrist.substack.com/p/part-51-human-desires-why-cev-coherent
3.2 https://doxometrist.substack.com/p/you-wont-believe-these-9-dimensions
4 (techo)animist trends
4.1 https://doxometrist.substack.com/p/riding-the-re-enchantment-wave-animism
4.2 https://doxometrist.substack.com/p/part-7-tpot-is-technoanimist
5 pagan/acc https://doxometrist.substack.com/p/pagan/acc-manifesto