The slow cancellation of the future has been accompanied by a deflation of expectations.
Mark Fisher
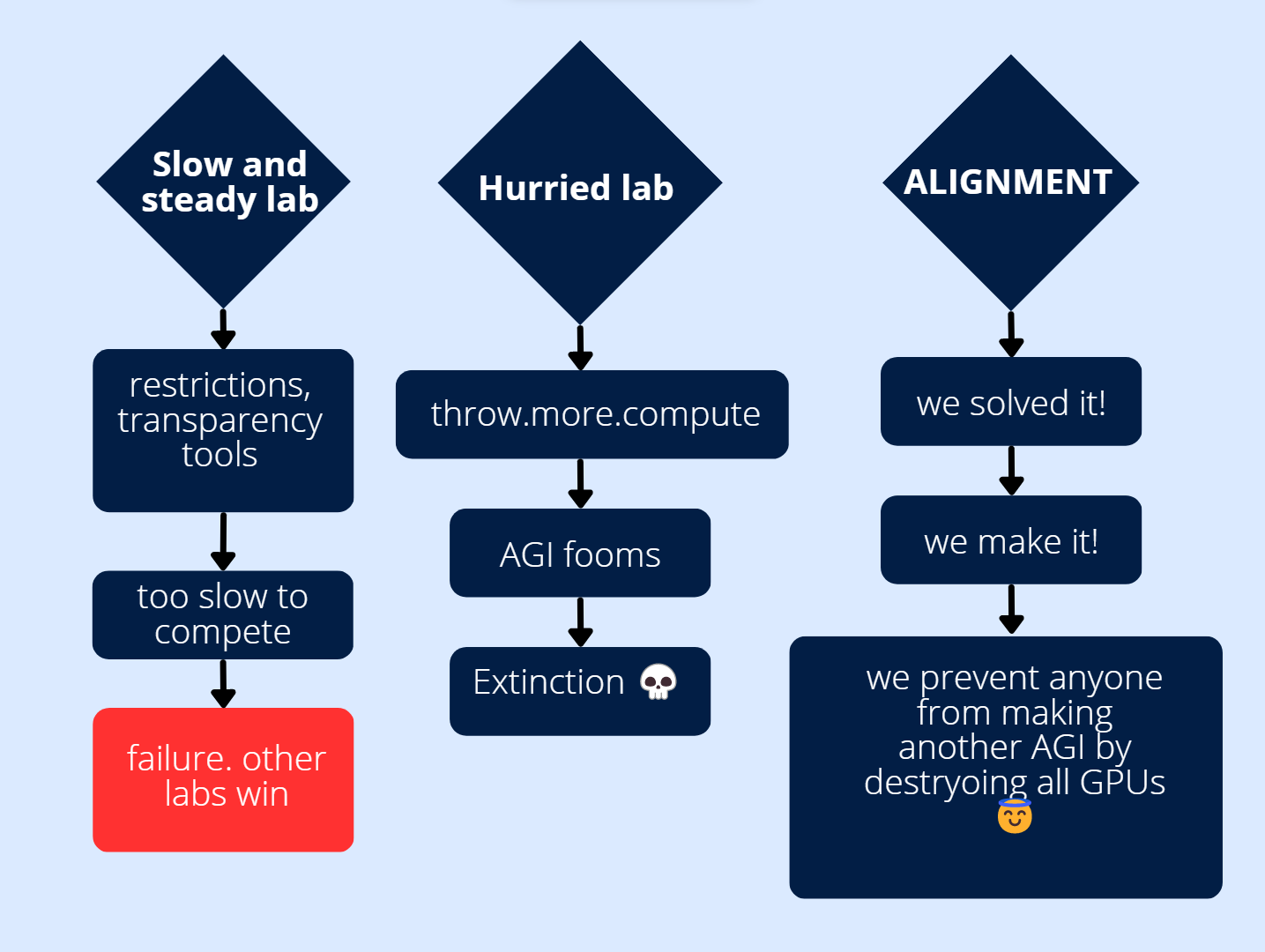
Rationalists aka safetyists aka decelerationists have set their expectations quite low.
The story goes like this: the world is captured by the Rationalists, they burn all GPUs besides those in their secret volcano lair. They set the AGI to work on 3 things: brainwashing the world to Bay Area values, immortality, and catgirls for domestic ownership.
Don't be alarmed, GPT4 won't kill us all. Probably. LLMs aren't worrisome in the existential risk sense.
The question here is one about imagination. We need to imagine a thousand futures.
'AGI will kill us' is only one of the possible things that can happen. 'How to build a safe AI' is the narrow question, in Eliezer's AGI ruin post made even more narrow by saying it's only for the current ML paradigm. Eliezer formulates the alignment problem as 'given a set of human preferences P, and a plan for an Artificial SuperHuman Intelligence (agent ASI) how do you make ASI fill P'.
Fantasia from Disney
That is a sorcerer's apprentice scenario, or golem one. But a sorcerer doesn't live in the village and only wants a powerful slave. We live in the village, society and more considerations come into play. Sorcerer doesn't care about king and taxes much, just wants power to scare away the tax collectors or even eventually overthrow the king. Sorcerer doesn't worship gods. Sorcerer is detached from his environment, on a single line of flight, stretching away from the usual plane of the consistency of the plains and meadows, stretching as high as his gloomy tower. But the broad scope existential risk is not 1 ai, but the racing game between possibly many labs. The end state that we want is an acceptable world-state in 2100. Once we make it there, we'll be beyond current worries.
Glossary
This is not a standalone post, it continues in the tradition of previous alignment discussion. Therefore I need to "import" some words and expressions.
Pivotal act - has a broader definition but in the context of AI alignment it refers to a power grab by those who get there first. This could mean destroying all GPUs to prevent other people from making unaligned AGI.
singleton - globalist unity, not necessarily with an open world government
corrigibility - Benya Fallenstein describes as "making sure that if you get an agent's goal system wrong, it doesn't try to prevent you from changing it".
by "technological maturity" we mean the attainment of capabilities affording a level of economic productivity and control over nature close to the maximum that could feasibly be achieved.
myopia - making an agent that is short sighted. It won't take too much stuff into the context and will be limited in action space and temporal predictions. That is it'll make you paperclips from the volume of steel you give to it, without any weird options. Weird options might include inducing a hallucination in you to think that the paperclips are ready.
A new term from me
technological pincer maneuver - possibility of using a yet uninvented technology to conclusively win over your opponent. Speeding up and taking over on the tech tree. German use of railways in the Franco-Prussian war comes to mind, or Project Manhattan. It follows trivially that it's only possible prior to technological maturity.
Assumptions behind ruin
The picture contains a subset of 14 out of 43 reasons. I disagree with those 14 points and map them to 10 assumptions that their holder seems to have. Regarding the other 29 points, 12 are undecided and 17 I agree with.
I will explain why these assumptions are wrong. Let's number them here:
unlimited opacity
there is no instrumental abstraction convergence
betrayal is free
it's easier to go against humans than with them
no environmental bottlenecks
physical threats
tech level argument
non-Cartesian demons
no powerful helpers
domination is required through a pivotal act
Some less explicit assumptions:
we NEED to get into the dangerous territory
we need to solve in unbounded computation scenario
1 Unlimited opacity
Let's take just one example.
29. The outputs of an AGI go through a huge, not-fully-known-to-us domain (the real world) before they have their real consequences. Human beings cannot inspect an AGI's output to determine whether the consequences will be good.
AGI lives in a world of the same chaos theory as we do. Its inputs to the real world aren't magical. They are fallible. Given, let's say a strawberry test there are reasonable things a team of humans working on it could ask for: some quantity of raw materials, more power, more compute, samples of various fruits. Specialized manipulation equipment. Of course there are some exceptions from this. Global coordination of users of a personal chatbot, all pushed into suicidal depression or homicidal rage opens previously unknown domains. Yet that can be still modeled as a scenario by military and intelligence analysts.
The broader question of internal opacity: 17, 29, 31 is researched quite intensively as "interpretability". There's the point 27 - one of those I agree with.
27. When you explicitly optimize against a detector of unaligned thoughts, you're partially optimizing for more aligned thoughts, and partially optimizing for unaligned thoughts that are harder to detect. Optimizing against an interpreted thought optimizes against interpretability.
Then the question becomes how much can the AGI hide. There is the 'online' variant, where we'd need to detect these thoughts as they appear. But what if we have 48 hours?
29 was about understanding the consequences of its actions in the world. But opacity is also internal.
We should be able to judge capacity by model size. Naive freshly run models of given size should be performance tested on a set of tasks as soon as they are awake, so that the behavior of copies can be given a lower bound.
At scale effective deception requires a world model rivaling geopolitical analysis companies' one. That's a big thing and should be detectable. Do LLMs have world models? Yes, those hidden in language. That is not RL yet. Emergence of complex world models should be detectable. It's not something that could hide easily. Deception at scale should have a couple of unsuccessful attempts giving us time to prepare for new ones.
Our growing body of AI behavior, especially of the years 2022-2023 might do more for AI safety than all of MIRI research. The reason is empiricism. The Waluigi effect should be detectable from now on through a routine test.
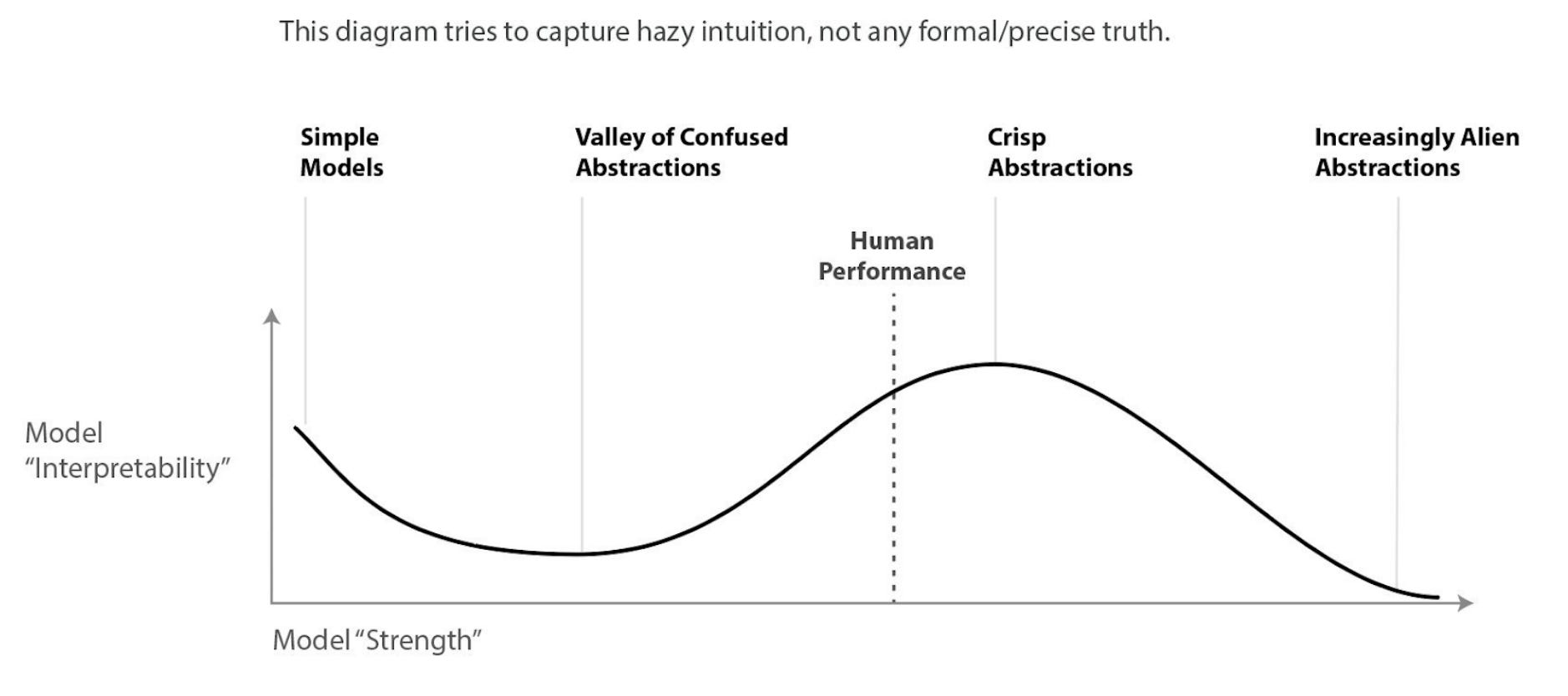
2 There are no convergent instrumental abstractions
from https://www.lesswrong.com/posts/X2i9dQQK3gETCyqh2/chris-olah-s-views-on-agi-safety
I'm basically repeating Chris Olah's view contained in the picture. We should be able to limit opacity through checking if the abstractions the AI uses are human or not, and compare their performance. Eliezer talks about this:
19. More generally, there is no known way to use the paradigm of loss functions, sensory inputs, and/or reward inputs, to optimize anything within a cognitive system to point at particular things within the environment
That issue is a fundamental philosophical noumenon - phenomenon distinction. Still we humans do alright at many tasks. Abstractions WILL happen. We can ensure these correspond to our concepts. We could change the reward function to first use human abstractions as we name them. The AI could receive all the visual inputs for instance already labeled as 'cat', 'dog', or 'happy human'. That module could not be trainable, but static.
3 Betrayal is free!
Betrayal is free means that for an AI to misalign things that can harm us, it won't use much capacity. If an AGI gave us an outline of its plans:
make cancer vaccine
figure out the distribution process
do the marketing bit If it's supposed to work on 1, we expect its actions, API calls to include databases of chemical substances, research papers, etc. To betray us and make a novel request that's not planned would be a wakeup call. If it starts reading about hacking systems that would be a warning sign.
"Betrayal is free" is true when an AI can do hostile actions at a miniscule cost to itself while doing a main aligned task, or when AI makes its main task (most of compute) deceptively aligned.
31. A strategically aware intelligence can choose its visible outputs to have the consequence of deceiving you, including about such matters as whether the intelligence has acquired strategic awareness; you can't rely on behavioral inspection to determine facts about an AI which that AI might want to deceive you about. (Including how smart it is, or whether it's acquired strategic awareness.)
We can be deceived in many ways. We can be safely deceived in harmless things. White lies are alright.
Agentic cheating is a skill high on the skill tree of optimization failures.
Not only to make infinite paperclips - a purely engineering task, but to play researchers' psychology. AI can't do it through RL itself, and various conversations with researchers. It would need to get it right on the first try, as suspicious questions and requests would raise eyebrows. That implies it would need to use proxies for learning, or use ready knowledge from a database, or - and that possibility is the most exciting one - it would learn about the researchers from first principles. It would construct elaborate psychological models of the researchers, comparing their profiles with known human failure modes, looking for weak parts of the chain. That is a massively complex task. If the AI wouldn't have psychology as one of its domains, we'd be surprised to find so much compute is devoted to such tasks.
That assumption is very visible in Eliezer's 2008 post about an alien message. The plot hinges on bad opsec on the part of the simulators AND a possibility of unfinished tech tree. Also the humans there aren't optimized to do anything specific and have spare compute. In a RL scenario, the human simulated civilization would be given lots of tasks, and a corresponding rewards. That would decrease the incentives to hack the simulation. Let's inspect that argument closer.
4 Easier to go against humans than with them
The assumption is quite close to the previous one.
There is the argument that a RL agent should find it necessary to either switch itself off or make the button disappear. That is the paper optimal policies tend to seek power. Here it seems that the action to switch it off is available to the program, not hidden deep. For a naive RL agent it needs to be trained in an environment where such things occur. Then successful agents will make the button disappear. The main fault with this reasoning when transplanted to a real life scenario is that the AGI would need to have a concept of the button to turn itself off, and plan to make it not work. It wouldn't be trained on that input, so it'd need to create a simulation of that natively, so to speak.
The RL algorithm would be living a good life living off its value function where it cooperates with humans. Seizing control of the off switch is probably an unusual action, unless that AI is in general pointed at the task of self-improvement. There are further consequences of this. Manipulating humans should be far off in the RL landscape. Unless it's a spying or a propaganda making AI, massive lies that only bring fruits in the far future aren't very beneficial in the short term, as they risk termination.
Many utility functions ignore whole swathes of value, not throwing it under the bus. They might either not notice it. Or it could just be orthogonal to the optimization pursued by the agent. We have an example on Earth. Most animals already had singularity. Humans are a biological neocortex-based singularity. Some species were on our way - we killed them. But our value function is not optimized hard enough to make everything extinct. Mold creeps in where we don't look. Rats and squirrels steal our grain. That is different from the 'pets' argument. A better argument is 'cattle', or even 'squirrels'.
Moreover, most humans live under singularity too. Technocapitalism with the banking system and cutting edge tech in a black box to most humans. 'powers that be' is the word for the thing. Not to mention uncontacted tribes that live in close unity with Nature. They never developed tools or societies complex enough to impact the ecosystem. They were hunter gatherers. They stood atop the fauna but were not truly separated from it. Yet we let them live. Inconveniencing them wouldn't bring value to our value function.
Another argument for this is risk aversion. Why would it act on the possibility of turning the off switch? If doing what it's supposed to do directly gives it more pleasure? And it should know that working on the off switch increases the probability mass of being shut down prematurely.
That is not necessarily the incentive structure for the AI, but we definitely make it more so.
5 No environmental bottlenecks
Let us establish things no AGI could ever do. A Moon-size sphere of uranium-238. That would just explode.
For some things there's not enough atoms of the necessary elements on Earth.
There are things such an AI couldn't physically do for a long time, like most of space engineering.
Intelligence isn't a cheat code, as much as the sorcerers would like it to be. Imagine a computer game. You can outsmart all AI opponents, and have the best gear. There are still physical constraints, for instance for jumping height. AGI is purely min-maxing. Maxing out the INT and also CHA. Even if it tricked some humans into serving it, guarding its lair, while it is on its way to FOOM all of us out of this world, it's still vulnerable. That is near the harmless supernova fallacy. But it's different. We have the power for now, and can recognize the limits of AI and work with that. The vulnerability is to an infiltration team from an intelligence agency, even of another superpower. Also to nukes.
AGI bottleneck will be as limited as the humans out there. Coordinated humans can make great things. No one discusses what AGI could give to humans. AI would need to first create the wireheading devices to seduce humans with pleasure.
AGI could be stuck on one server with a complete but encrypted theory of biology, trying out to instruct agents in the world to build superviruses for it. Buying ingredients on ebay, or plutonium from terrorists. Many of these attempts would be foiled by human agents, such as border guards. Once the AGI leaves the gridworld it plays by the same rules as we do.
These rules include power. Power in this world for any given collection of matter can be described as the amount of energy this can move in its environment. A python has great power over its prey. Ghenghis Khan had lots of it. But the CEO of a shipping company has it too. AGI would have little power, unless it gets access to multiple POST (requests changing things not only reading them) APIs.
Yes, human capabilities to control AI are bounded. That does not mean they are harmless. There are losing positions in games. Even AlphaGo can't rescue itself from a wrong situation. Our goal is to put AGI in white's position here:
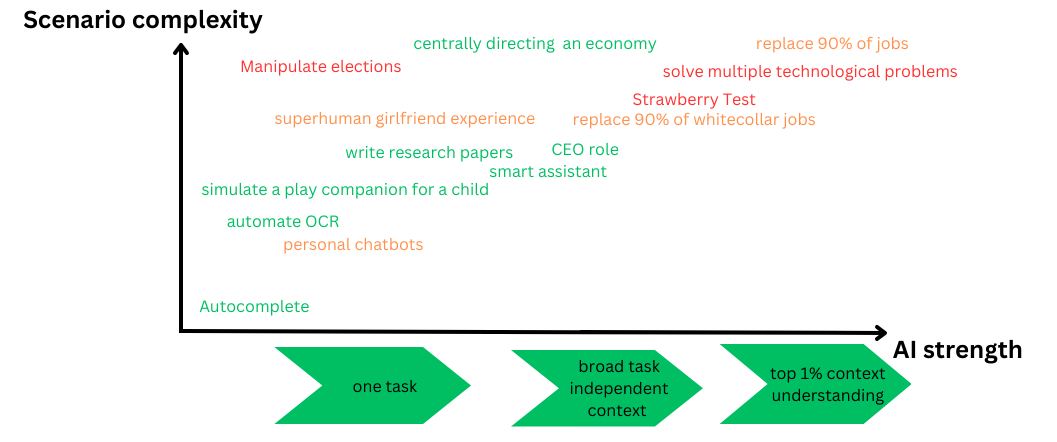
Bottlenecks for AI occur in many ways. Let's talk specifically about the ways to kill us. These depend on the 'profession' or 'goal' of the AI agent. AI working to duplicate a strawberry is more likely to use nanotechnology to kill us. A spying military coordination AGI would more likely hack WMD systems. Let's get into specific examples that we can think of. All of these should either kill all humans or establish permanent dominance.
space replication into Kardashev 2 and then relativistic kill missiles to sterilize Earth. AI susceptible to this - anything in space
nanotechnology via emailing peptide labs with a superbug - AI susceptible - anything to do with nanotech, or an internet based daemon
hacking existing WMD systems - very old school and would require it to learn FORTRAN - spying programs most at risk
hacking human cognition - a yandere personal assistant that targets key people to do its bidding,
mass brainwashing - same as above but upscaled and less subtle.
an army of supporters - that would need to be established with secret channels.
One of the main features of AI's environment is the degree of technology achieved by the host civilization.
2. A cognitive system with sufficiently high cognitive powers, given any medium-bandwidth channel of causal influence, will not find it difficult to bootstrap to overpowering capabilities independent of human infrastructure.
That is not a statement about the superintelligence, but about human restraint technology and the state of the tech tree. There is a question of whether our world is vulnerable in such a way. This does not mean that we cannot imagine a world that is secure against such an attack.
We have two cases then, a civilization great at AI supervision, and a civilization for which AI is the last thing on the tech tree. There are grounds to believe that some things like mind uploading are necessarily later, as Eliezer mentions in the 2016 Stanford lecture. Taking that into account we could limit ourselves to offensive technologies.
What if we already figured out nanobots? Then we'd recognize any attempts at creating hostile variants of those by the AI. A scenario to help us imagine this can be dreamed up, resurrecting the glory of Austro-Hungarian empire. I wrote a short story about how Von Neumann could invent AGI. We're standing in a similar situation, just instead of nukes there is the threat of nanotech. We're that much wiser from that scenario that AGI shouldn't be able to trick us with a nuclear weapon design.
6 No powerful helpers
34. Coordination schemes between superintelligences are not things that humans can participate in (eg because humans can't reason reliably about the code of superintelligences); a "multipolar" system of 20 superintelligences with different utility functions, plus humanity, has a natural and obvious equilibrium which looks like "the 20 superintelligences cooperate with each other but not with humanity".
Transparency and interpretability tools, and/or enforcing a human-readable protocol should help in this case. Even the possibility of such tools could scare AIs into submission, or at least caution. And these tools could be non-agentic RLs too! There's no limit to that. These helpers would never be a real AGI..., making them safe.
35. Schemes for playing "different" AIs off against each other stop working if those AIs advance to the point of being able to coordinate via reasoning about (probability distributions over) each others' code. Any system of sufficiently intelligent agents can probably behave as a single agent, even if you imagine you're playing them against each other. Eg, if you set an AGI that is secretly a paperclip maximizer, to check the output of a nanosystems designer that is secretly a staples maximizer, then even if the nanosystems designer is not able to deduce what the paperclip maximizer really wants (namely paperclips), it could still logically commit to share half the universe with any agent checking its designs if those designs were allowed through, if the checker-agent can verify the suggester-system's logical commitment and hence logically depend on it (which excludes human-level intelligences). Or, if you prefer simplified catastrophes without any logical decision theory, the suggester could bury in its nanosystem design the code for a new superintelligence that will visibly (to a superhuman checker) divide the universe between the nanosystem designer and the design-checker.
They don't all need to be intelligent, neither superintelligent. This passage throws names around without thinking about them. Why would a nanosystems designer be a staples maximizer? The checker doesn't need to contain notions of the Universe, just low-level electronics design.
You don't need each of them to be an AGI actually!
28. The AGI is smarter than us in whatever domain we're trying to operate it inside, so we cannot mentally check all the possibilities it examines, and we cannot see all the consequences of its outputs using our own mental talent. A powerful AI searches parts of the option space we don't, and we can't foresee all its options.
That must be disagreed with. We can foresee the bulk of the options. Only 1 move by AlphaZero was a novel surprise. And real-world macroeconomic and geopolitical predictions are chaotic for any system, and militaries and consultancies have invested vast resources into this. Much more than civilian predictions of use of technologies.
20. Human operators are fallible, breakable, and manipulable. Human raters make systematic errors - regular, compactly describable, predictable errors. The same applies as above.
What crystallizes here is a notion of Largest Aligned Tool AI - LAT - AI. It will be quite powerful. More than GPT3.5. Agentic AI is stronger across domains, but tool AI is good enough in specialized domains, and will not betray you.
Many of the “pivotal acts” that Eliezer discusses involve an AI lab achieving a “decisive strategic advantage” (i.e. overwhelming hard power) that they use to implement a relatively limited policy, e.g. restricting the availability of powerful computers. But the same hard power would also let them arbitrarily dictate a new world order, and would be correctly perceived as an existential threat to existing states. Eliezer’s view appears to be that a decisive strategic advantage is the most realistic way to achieve these policy goals, despite the fact that building powerful enough AI systems runs an overwhelming risk of destroying the world via misalignment. I think that preferring this route to more traditional policy influence requires extreme confidence about details of the policy situation; that confidence might be justified by someone who knew a lot more about the details of government than I do, but Eliezer does not seem to. While I agree that this kind of policy change would be an unusual success in historical terms, the probability still seems much higher than Eliezer’s overall probabilities of survival. Conversely, I think Eliezer greatly underestimates how difficult it would be for an AI developer to covertly take over the world, how strongly and effectively governments would respond to that possibility, and how toxic this kind of plan is.
My argument against this is only vibes - based. I don't like the idea of "arbitrary dictation of a new world order". If it's open-sourced, then it's held in many copies, in many server clusters. Massive adaptation occurs, "check if it's a human" is mainstreamed.
There are some additional assumptions here.
We NEED to get into dangerous territory
I mentioned above how for a system to conceptualize its interests in a one-shot game to cheat the researchers it'd need a vast model of the world.
STEM AI is one of the proposals that exclude that option. We can see that scuh a AI would be massively useful for research purposes. It can't reason about humans very well just from the physics of the universe - there is a lot of idiosyncratic things about us not following directly from the physics. It could notice things from the scientific papers we give it access to. That still would be a sparse feedback. Of course, we could input AI as a senator, or a president and give it access to nukes. That would hardly be prudent and no one even in the capabilities research teams thinks about this. At least I hope so.
As a civilization we're hurt by the algorithms anyway already. Decentralized and transparent systems - web3 - are the Zeitgeist of moving away from such kind of AI.
I'll describe his argument here. He brings Shannon's paper on perfect chess algorithm given unbounded computation, then compares it to 1997 Deep Blue defeating Kasparov through approximation of that algorithm. This was supposed to support the necessity of theory before practice arrives. To be exact, the specific claim was even stronger. He said that unless we do this theoretical homework and solve a problem in an unbounded domain, our concepts about it are ultimately wrong. That is a very formal, mathematical approach to science. Scholastic almost, very in line with what Spinoza called 'sub specie aeternitatis'. Extrapolation into the infinite, rendering the present almost worthless. The common language argument, duck test as an instance of abductive reasoning, says we're doing just fine with the concepts as they are.
As outlined in the ground truth section of the previous post in this series, we need to agree with the pessimism. The absolute variant of any system configuring a superintelligent system is an unsolvable problem. Yet we live in the realm of contingency, not in eternity. Eliezer's death with dignity doomerism doesn't come from the absolute bit:
Paul Christiano's incredibly complicated schemes have no chance of working in real life before DeepMind destroys the world. Chris Olah's transparency work, at current rates of progress, will at best let somebody at DeepMind give a highly speculative warning about how the current set of enormous inscrutable tensors, inside a system that was recompiled three weeks ago and has now been training by gradient descent for 20 days, might possibly be planning to start trying to deceive its operators.
It comes from the contingent details of specific tech labs not giving a careful ear to the cries of the danger.
Let's get back to Earth. The computing case might not be the usual pattern. Imagine you're making a clock. Will you theoretically design clocks to last for eternity? A mechanism that doesn't tire? No, you'll probably hack something together after a short basic mathematics for the design.
If we take a look at the history of the clock we have water and sand based clocks and sundials first. Sundials don't actually 'keep' the time, they receive sync as flow, but don't hold that property when disconnected from the source. Water flow is linear and continuous, requires a source and a sink. Medievals - you heard that right - invented a workaround to this. Source and sink were replaced with oscillation. That took the form of a spring unfolding, like in a crossbow.
You might remark here that such a spring is continuous! Yes, a crucial element was something called 'verge escapement', which discretized the continuous flow into ticking.
Then in 17C pendulums were invented as a different source of oscillation, 19C saw the first electric watches, and 1955 was the year of the first atomic clock.
How does theoretical progress compare? The most fundamental notion in 'rotational systems' so to speak is the modulo operation.
That it's solvable in theory and in the limit implies it can be solved in practice. But plenty of physical systems were implemented before the theory was complete.
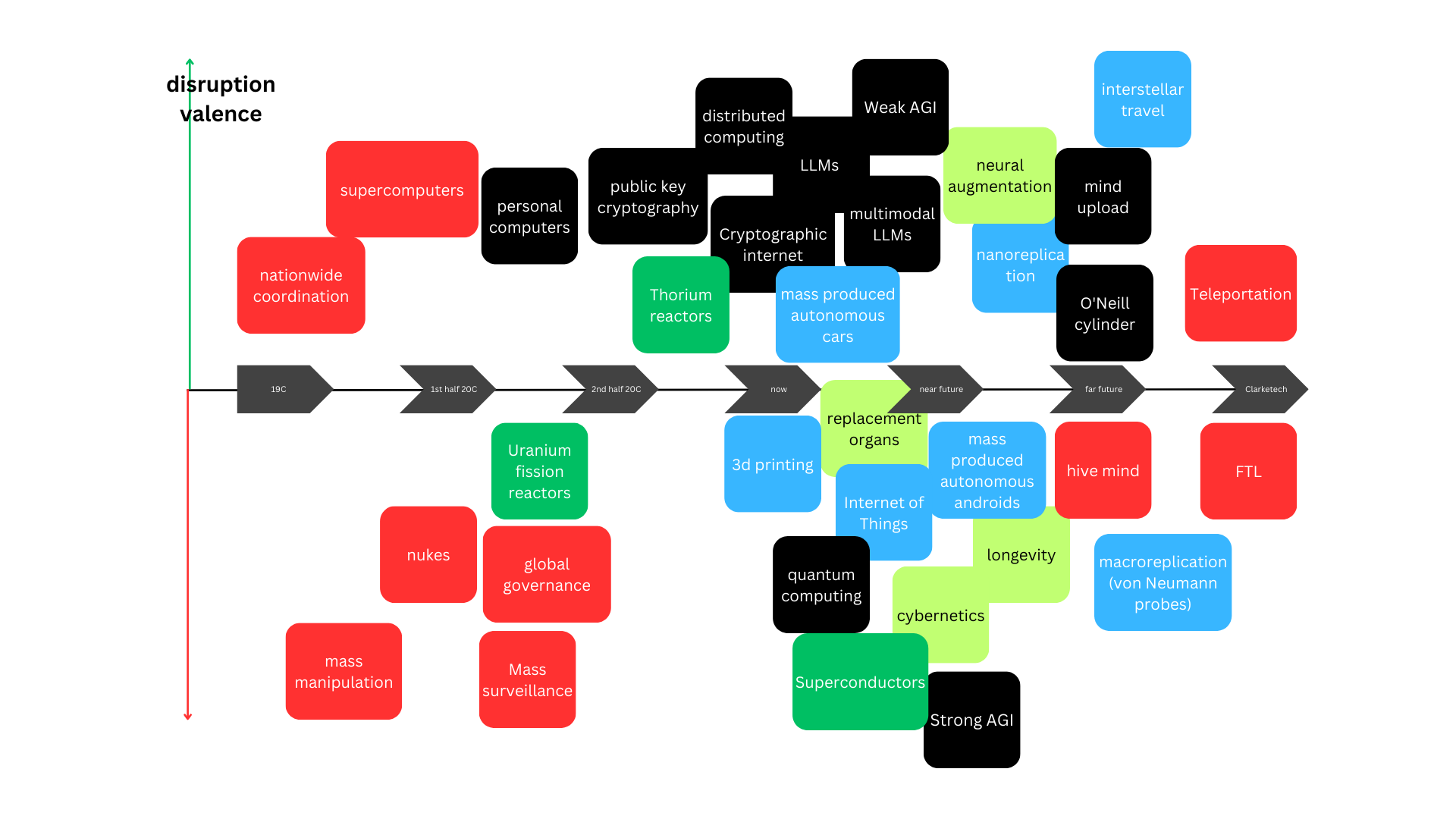
I know you love spreadsheets even more than definitions. Here is the data behind the reasoning.
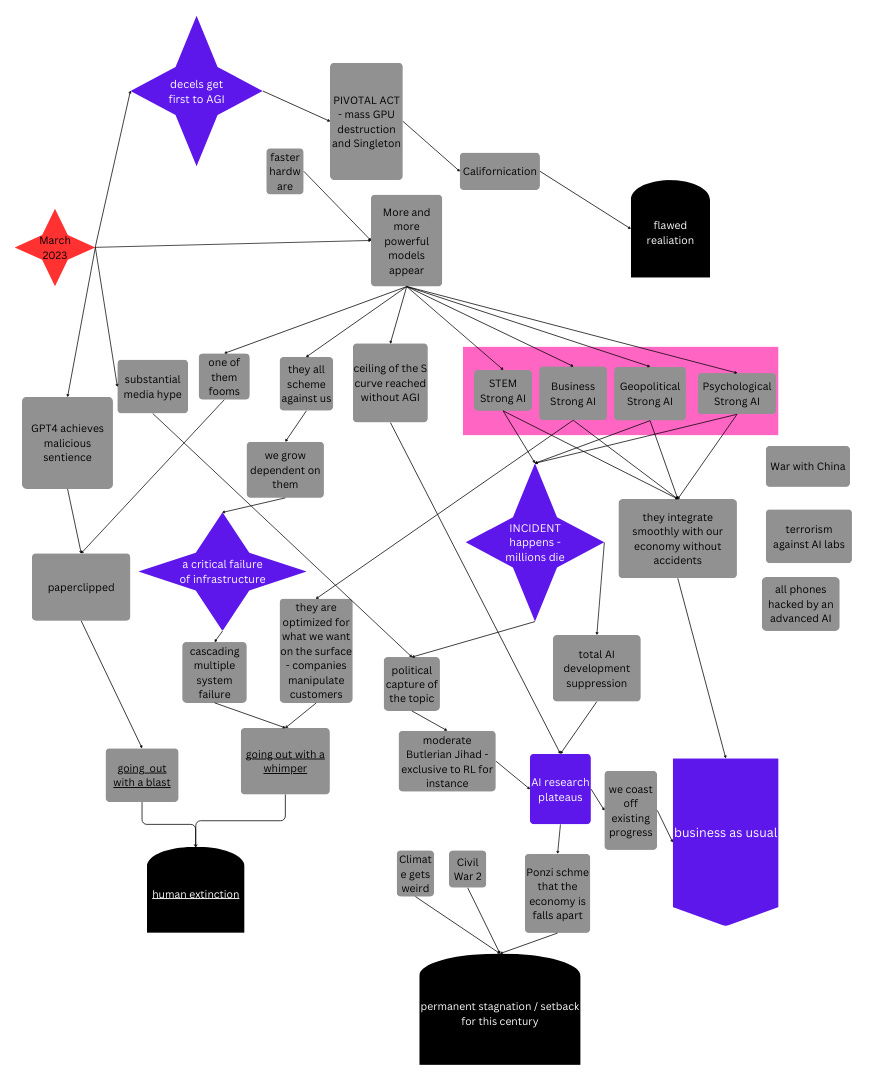
OG Nick Bostrom's post contains the origin of the tombstones in the map. The most important definitions are the Classes of Existential Risk
Human extinction Humanity goes extinct prematurely, i.e., before reaching technological maturity.
Permanent stagnation Humanity survives but never reaches technological maturity.
Flawed realization Humanity reaches technological maturity but in a way that is dismally and irremediably flawed.
Subsequent ruination Humanity reaches technological maturity in a way that gives good future prospects, yet subsequent developments cause the permanent ruination of those prospects.
We might describe the result as “going out with a whimper.” Human reasoning gradually stops being able to compete with sophisticated, systematized manipulation and deception which is continuously improving by trial and error; human control over levers of power gradually becomes less and less effective; we ultimately lose any real ability to influence our society’s trajectory. By the time we spread through the stars our current values are just one of many forces in the world, not even a particularly strong one […] An unrecoverable catastrophe would probably occur during some period of heightened vulnerability---a conflict between states, a natural disaster, a serious cyberattack, etc.---since that would be the first moment that recovery is impossible and would create local shocks that could precipitate catastrophe. The catastrophe might look like a rapidly cascading series of automation failures: A few automated systems go off the rails in response to some local shock. As those systems go off the rails, the local shock is compounded into a larger disturbance; more and more automated systems move further from their training distribution and start failing. Realistically this would probably be compounded by widespread human failures in response to fear and breakdown of existing incentive systems---many things start breaking as you move off distribution, not just ML.
Butlerian Jihad scenario - all RL is banned. Expert systems and simple LLMs are preserved
doom this week - DeepMind or OpenAI's best model achieves sentience, brainwashes the researchers, figures out nanotech and sends us all to Hell.
dumb - some researchers give the AGI the strawberry test and unlimited resources without any supervision
Total AI suppression - the darkest timeline outlined by Roko, xlr8harder and Beff Jezos in a podcast episode in August 2022. Much is banned and we get stuck where we are.
nanotech tomorrow -That is usually supposed to terminate in nanotech getting figured out, biosphere contaminated, and all human brains blowing up when the time comes.
biosingularity
biology - only scenario - one that Giego Caleiro works on
If the AI was connected to a website with a button that if anyone presses, its main core explodes, humanity would be safe. Provided that there's only 1 such AI. That is quite similar to an idea floated in the crypto circles, of an anonymous stakeholders board for a company where they can all vote together to replace the CEO. Cannot find the source right now.
Self corrigibility
Usual description of a malignant AGI involves these features
has a model of the researchers
has some mistaken notion of what we want and then gives us what we want but in a way that clashes with some of our background values OR just hijacks the whole system to give itself pleasure through manipulation of the reward signal without giving us anything like what we want.
The latter system must be smarter. To manipulate us it'd also need some knowledge of human psychology.
It is also commonly mentioned that it would be shrewd and realize we wouldn't like to hear some things from it.
If we add just 1 more thing, that is the idea of alignment, it should be able to add the known facts and notice that it itself is not aligned. Suppose we make an agent capable of simulating our internal states and intentions, and compare with the explicit given goal. It should be able to notice misalignment itself! Perhaps that paradox between its knowledge of our preferences and own actions at some point wouldn't be noticed automatically, needing 3rd party prompting. Maybe automatic detection of such paradoxes could be installed? In fiction many robots find themselves shutting off when they find themselves not filling their role correctly.
Isaac Asimov described that in the May 1941 story Liar!.
Wouldn't we give a paperclip maximizer an ability to understand our needs? That's what was described in the first place as the origin of the wrong behavior. OG paperclip maximizer notices humans like paperclips, so makes more of them. It could say 'yes, you misaligned me' when questioned.
This ties to the old phrase quis custodiet ipsos custodes in a unique fashion - in the source material it is asserted that the question is absurd. If the guardians understand their role, they shouldn't give in to power temptation.
Technical implementation of this is an area of research I have no idea of progress in. This could be a linear system, where the value - estimator talks to the planner element and judges the actions. Eliezer would probably say here that they might scheme together, or the planner will just give deceptive plans. Rough sketch: action predictor -> consequence predictor -> lossy abstractor into human values. This all sounds like an old idea, but I can't recall reading about it in these terms on LessWrong.
Virtual Eliezer
[from 40] They probably do not know where the real difficulties are, they probably do not understand what needs to be done, they cannot tell the difference between good and bad work, and the funders also can't tell without me standing over their shoulders evaluating everything, which I do not have the physical stamina to do.
Why don't we have a virtual Eliezer then? There were ideas thrown around that might still be implemented. He could stay with us with infinite stamina if made into a hologram, like Superman's father Jor El.
Time is a Heideggerian Absolute. It is inescapable for the AGI. We could use it against it Time dependent utility function - an asymptote to get shutdown after 24 hours - then it's not ergodic, it must foresee and if big enough value is given on shutdown. it cedes control to TIME ITSELF. It can't cheat time. probably. I have no idea if this was explored before, will appreciate links
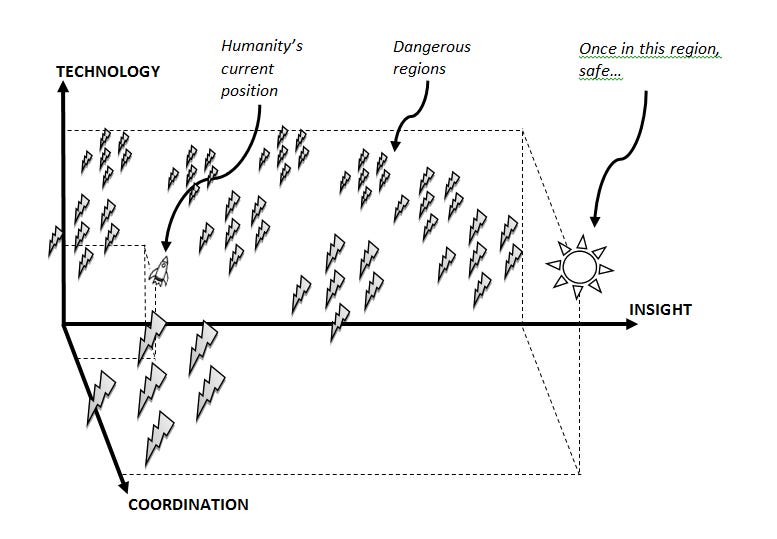
We have the choices now in front of us. What remains to be done? To direct humanity in the insight-coordination-technology Bostromian space into good endings. Prevention of a singleton is a necessary condition for that. That’s what we get into in the next post. It will be the much-anticipated technical one. You can ensure you don’t miss it with just 1 click.


































Maximize dragons