


Pagan / Acc Chapter 2.3
Tech stack for Anarchist AI

A spectre haunts the noosphere - the spectre of competition in the realm of AI.

https://twitter.com/Outsideness/status/1639306179108122624
Powers that be fear destabilization.
https://twitter.com/0x49fa98/status/1641767154746900480
In the previous post, we examined the potential of decentralized AI. A world with decentralized access to real-value production through accessible AGIs is much better than centralized power and serf money from Worldcoin.

In this post I go into the specifics. The tl;dr is this table:
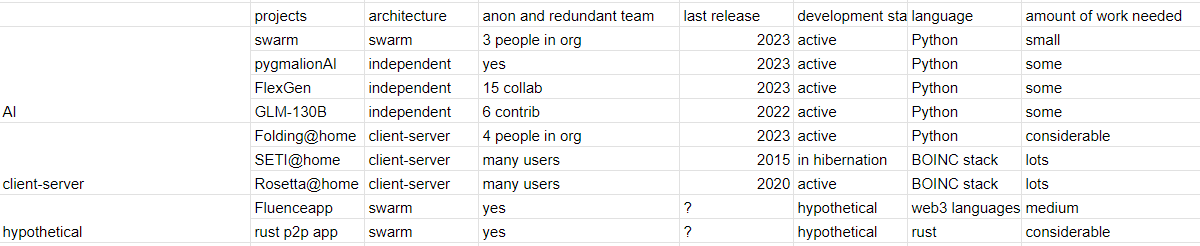
This information was collated in March, before the hiatus I had on this blog so it might be 100% up to date concerning the AI projects. There are also surely more projects than that.
Decentralized vision
It’s 2027, you turn on your computer and it welcomes you with a voice interface. It tells you it has been syncing the latest update of the new training. You ask about the contents of that specific training. It tells you it was one of the last raw Sanscrite texts that haven’t been integrated into the network. All English texts and petabytes of pictures had been added years ago.
Your computer is but a node in a network. Training is decentralized, but you run your own customization through 24/7 RLHF, and inferences are very cheap computationally. Weights for the model are saved in a decentralized way, your node grabs the latest version every few hours and applies the mask of personalization towards you. It also runs training on a given sample that is later verfied by other nodes, kind of like Bitcoin, with Proof-of-Training instead of Proof-of-Work. Your node client is open source and in Python, but many people use an embedded one for smartwatches that’s in Rust.
There is a couple of choices that are necessary to build the Anarchist AI.
Architecture and messaging model that handles the parallelism in training
Source of training data
Communication protocol between the nodes
Storage of weights
Programming languages
This is more of a list of links for consideration than a full article. This could be a basis for a whitepaper for the Anarchist AI, but that is not something I am capable of undertaking alone. I’m sure some of the more experienced software dev frens could do something great with this.
Parallel training
In a wide sense, parallel training is used already, but on the small scale in the CUDA hardware stack used on the cutting edge GPUs. There has been some research on the expansion of that parallelism
ARXIV paper on merging models from March 2023
Discussion on Parallelism techniques from huggingface
2017 paper by Lee et al for distributed-memory computing environment: Parallel Deep Convolutional Neural Network Training by Exploiting the Overlapping of Computation and Communication
a course on writing CUDA functions from akshat0304
together.xyz, a company (?) making an open access AI cloud
Sources of data for training
These should be easily accessible and good for the use case. It doesn’t seem that the bottleneck to AGI goes from the lack of training data.
I heard Lib-Gen is good too for this
a bit tangential, but a paper on providing CNNs with multi-dimensional input - book correlated with corresponding video
this twitter discussion on the size of the training and argument that publicly available text is quite more than about for a trillion parameters
the Pile Dataset would be a good starting point for a proof-of-concept for a distributed training setup
twitter discussion on the sources of training for LLAMA
common crawl, the goto dataset containing websites
Ok, let’s assume we come to some good parallel architecture and settle on a dataset for training. All that remains is communication between nodes of the network, method of storage of weights and the programming languages used.
Communication protocols
I won’t leave much room for debate here. The easiest protocol for mass p2p file sharing already exists, and it’s BitTorrent. The task here would be to make a client that would only deal with weights and dataset files, and run the distributed training. Here is a list of BitTorrent clients, mostly open source, that would be forked or at least possibly mimicked architecturally.
BitComet - made by a Chinese company, surrounded by some controversy around tracking
proprietary adware BitTorrent client - the first client
Deluge client, written in Python interface and C++ networking logic
FrostWire - with a version for Android and in Java (sad fr)
qBittorrent C++ backend library with search engine in Python
Transmission - Objective C++ - allegedly default client in many Unix and Linux distros
Tribler - an open source client with emphasis on anonymity in Python
libtorrent a C++ implementation of the client, v2 release notes
rqbit - a Rust implementation, more of an exercise in Rust than a feature-complete product
torrust-tracker - a high performance Rust implementation - last release May 16, 2022
Bit Torrent Speed with an incorporated token incentive system on the blockchain
Storage of weights
Of course, storage with the bittorrent protocol is covered but redundancy would be good. Additional options can be considered for storing the HDF5 weight files.
as the approach would be read heavy, not write heavy, formats like Apache Parquet might be useful
Storing AI Datasets on Decentralized Web - 2022 article from Filecoin Foundation
a bit odd November 2018 article about the use of blockchain with torrenting
More on the topic of torrents x blockchain on medium from July 2018 post
If the whole system uses blockchain heavily, the weights would be queried through oracles
Programming language choices
The project is at the cross of machine learning and networking, therefore a tech stack and language that has good support for either seem the best choice at the first glance. One key concern is the full use of GPUs through the CUDA language. Python has official support from NVIDIA and API bindings. If Rust is to be the competitor, its CUDA support is quite weak. I only managed to find this repository, that is not maintained. Using Rust here might not be the good play here, especially as Python’s ‘child", Mojo promises to solve such issues.
Nevertheless we might consider Rust option just for fun - or performance and safety advantages! 🦀🦀🦀
Rust option
here we have Rust transformer sketch (last updated Apr 2022)
rust_bert for use in NLP pipelines
for the networking part there’s an ongoing project with rust-libp2p with the corresponding tutorial
arewelearningyet is a site that tracks the degree of development of ML tooling in Rust. RL is not doing so great. Here is a more general reddit discussion.
finalfusion library for word embeddings
if the options above cover the ML and networking bit, tauri would provide an excellent desktop UI
As this is effectively a distributed programming project, some analysis of previous attempts is in order. Constellation-rs was one such attempt, with no updates since 2021, with one repo for distributed programming and the other one for data analysis
Now in the scenario we don’t like to extend any torrent client nor build a full Rust solution, we could use a project that has networked distributed computing at its core, the fluence project. It uses formal pi-calculus and a custom language, as well as runtime, and runs in WASM, so you can have in the browser. See docs for more details. See also app examples, one for NFTs one for Rust scripting with Lisp.
Summary
It does not look like the choices are too hard. The path of least resistance seems to fork a Python bittorrent client, combine it with running an LLM locally (such as with Petals) and provide an excellent UI that can be run on many kinds of hardware. The key conceptual bit is massive parallelization of training online in a p2p environment. That doesn’t seem impossible and a focused team should be able to create a working MVP within a few months if not weeks. Then the local inference seems relatively trivial. Of course the tech is only the necessary condition for a decentralized anarchist AI, memeing it into popular use to rival the adoption rate of projects like SETI@home is the logical next step.
I myself am not up to the task of implementing the ideas discussed here, at least not alone. Let me know in the comments if you like the idea.
Links to other parts:
rats and eaccs 1
1.1 https://doxometrist.substack.com/p/tpot-hermeticism-or-a-pagan-guide
1.2 https://doxometrist.substack.com/p/scenarios-of-the-near-future
making it 22.1 https://doxometrist.substack.com/p/tech-stack-for-anarchist-ai
2.2 https://doxometrist.substack.com/p/hiding-agi-from-the-regime
2.3 https://doxometrist.substack.com/p/the-unholy-seduction-of-open-source
2.4 https://doxometrist.substack.com/p/making-anarchist-llm
AI POV 3
3.1 https://doxometrist.substack.com/p/part-51-human-desires-why-cev-coherent
3.2 https://doxometrist.substack.com/p/you-wont-believe-these-9-dimensions
4 (techo)animist trends
4.1 https://doxometrist.substack.com/p/riding-the-re-enchantment-wave-animism
4.2 https://doxometrist.substack.com/p/part-7-tpot-is-technoanimist
5 pagan/acc https://doxometrist.substack.com/p/pagan/acc-manifesto
I've been thinking about this. How would you implement proof of training? Simply evaluating the loss before and after won't cut it.